
ブラックボックステストとは?特徴、一般的な手法とテストの手順を解説

アノテーションとは?
データアノテーションは画像、映像などの学習用データにラベリングをする作業です。ご存じの方も多いと思いますが、機械学習アルゴリズムにはアノテーションされたデータが必要不可欠です。アルゴリズムが処理するためには、(品質の)アノテーションされたデータが必要だからです。
LQAのAIトレーニングプロジェクトでは、様々な種類のアノテーションを使用しています。どのような種類のアノテーションを使用するかは、主に、どのような種類のデータとアノテーションツールを使用しているかによって決まります。
6 つのアノテーションタイプ
バウンディングボックス:その名の通り、この方法はアノテーション対象物を長方形で囲む、というものです。この方法は主に、自動車、セキュリティ、eコマースに関連したデータに使用されています。
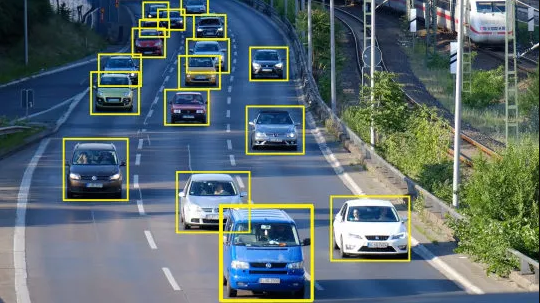
アノテーションタイプ:バウンディングボックス
ポリゴン: 人間の体、文字、看板など、特殊な形を正確に認識する際にこの方法を使用します。対象物を明確な線で囲み、対象物の形、大きさを正確に抽出することによって、より質の高い機械学習を可能にします。

アノテーションタイプ:ポリゴン
ポリライン:ポリラインは、バウンディングボックスの弱みを克服した方法と言えます。バウンディングボックスでは余分な面積も囲んでしまいますが、ポリラインではその面積をなくすことができます。この方法は、主にレーンや道路の画像に使用されます。

アノテーションタイプ:ポリライン
3Dキューブ:この方法で、対象物の容積をはかることができます。主に、車、建築物や家具に使用されます。
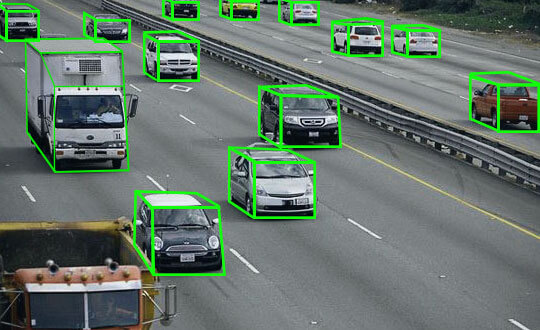
アノテーションタイプ:3Dキューブ
セグメンテーション:セグメンテーションはポリゴンと似ていますが、ポリゴンよりも複雑な方法です。ポリゴンは独立した対象物を1つ1つ選びますが、セグメンテーションは全てのピクセルに当てはまるラベルを付けていきます。そのため、この方法はより高度な認知を行うことができます。

アノテーションタイプ:セグメンテーション
ランドマーク:この方法は、人間のポーズや、顔に現れる表情やその感情の推定、検出に役立っています。ランドマークアノテーションに使用されるアノテーションツールは、特定の範囲内でのマークの密度を測ることも出来ます。

アノテーションタイプ:ランドマーク
関連記事:
プロジェクトに必要なデータ収集やアノテーションでお困りの際は、お気軽にご連絡ください!
- Website: https://jp.lotus-qa.com/
- Tel: (+84) 24-6660-7474
- Fanpage: https://www.linkedin.com/company/lqa/
Related posts





